
 KREBS-CHEVRESSON CLEMENT
b4533f720b
Update Evaluation.md
KREBS-CHEVRESSON CLEMENT
b4533f720b
Update Evaluation.md
|
6 years ago | |
|---|---|---|
| .idea | 6 years ago | |
| out | 6 years ago | |
| src | 6 years ago | |
| Evaluation.md | 6 years ago | |
| P4a.iml | 6 years ago | |
| README.md | 6 years ago | |
| acceder_mem.png | 6 years ago | |
| acceder_mem_appro.png | 6 years ago | |
| acceder_tps.png | 6 years ago | |
| acceder_tps_appro.png | 6 years ago | |
| appronfondie.sh | 6 years ago | |
| fichier.txt | 6 years ago | |
| perf.dat | 6 years ago | |
| perf_hypothese.dat | 6 years ago | |
| plot.r | 6 years ago | |
| plot_approfondie.r | 6 years ago | |
| recherche | 6 years ago | |
| recherche.c | 6 years ago | |
| remplir_mem.png | 6 years ago | |
| remplir_mem_appro.png | 6 years ago | |
| remplir_tps.png | 6 years ago | |
| remplir_tps_appro.png | 6 years ago | |
| run.sh | 6 years ago | |
| supprimer_mem.png | 6 years ago | |
| supprimer_tps.png | 6 years ago |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
README.md
P4a : Analyse de performances de différentes structures
Problème
Description du Problème.
Au cours du développement d'un programme en informatique, le collections comme Arraylist, hashmap ou encore vector sont souvent utilisées. Ainsi il convient de se demander lesquelles sont les plus appropriées pour certaines opérations.
Description de tous les paramètres exploratoires du problème
Comme dit précédemment, l'étude portera sur les arraylist, hasmap et vector. Les opérations étudiées sont :
- Remplir avec comme valeur un entier au hasard
- Supprimer une valeur, la position est prise au hasard
- Accéder à une valeur, la position est prise au hasard
Dispositif expérimental
Application
Pour lancer l'application : java -jar P4a.jar <strucutre> <operation> <nombre_occurrence>
Description de l'application et des arguments
structure :
arraylist
array
hashmap
operation :
remplir
supprimer
acceder
nombre_occurrence : le nombre d'éléments à traiter
Les opérations supprimer et acceder procèdent d'abord à un remplissage.
Environnement de test
Description de la plateforme de test
Description processeur (lscpu) :
Architecture : x86_64
Mode(s) opératoire(s) des processeurs : 32-bit, 64-bit
Boutisme : Little Endian
Tailles des adresses: 46 bits physical, 48 bits virtual
Processeur(s) : 40
Liste de processeur(s) en ligne : 0-39
Thread(s) par cœur : 2
Cœur(s) par socket : 10
Socket(s) : 2
Nœud(s) NUMA : 2
Identifiant constructeur : GenuineIntel
Famille de processeur : 6
Modèle : 79
Nom de modèle : Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz
Révision : 1
Vitesse du processeur en MHz : 1498.682
Vitesse maximale du processeur en MHz : 3100,0000
Vitesse minimale du processeur en MHz : 1200,0000
Description ram (free -h) :
total
Mem: 125Gi
Swap: 127Gi
Description de la démarche systématique
Description de la démarche systématique et de l'espace d'exploration pour chaque paramètres.
Suite des commandes, ou script, à exécuter pour produire les données.
./run.sh | tee perf.dat pour la production des données
r plot.r pour le traitement des données et la production des graphiques
Résultats préalables
Temps d'exécution
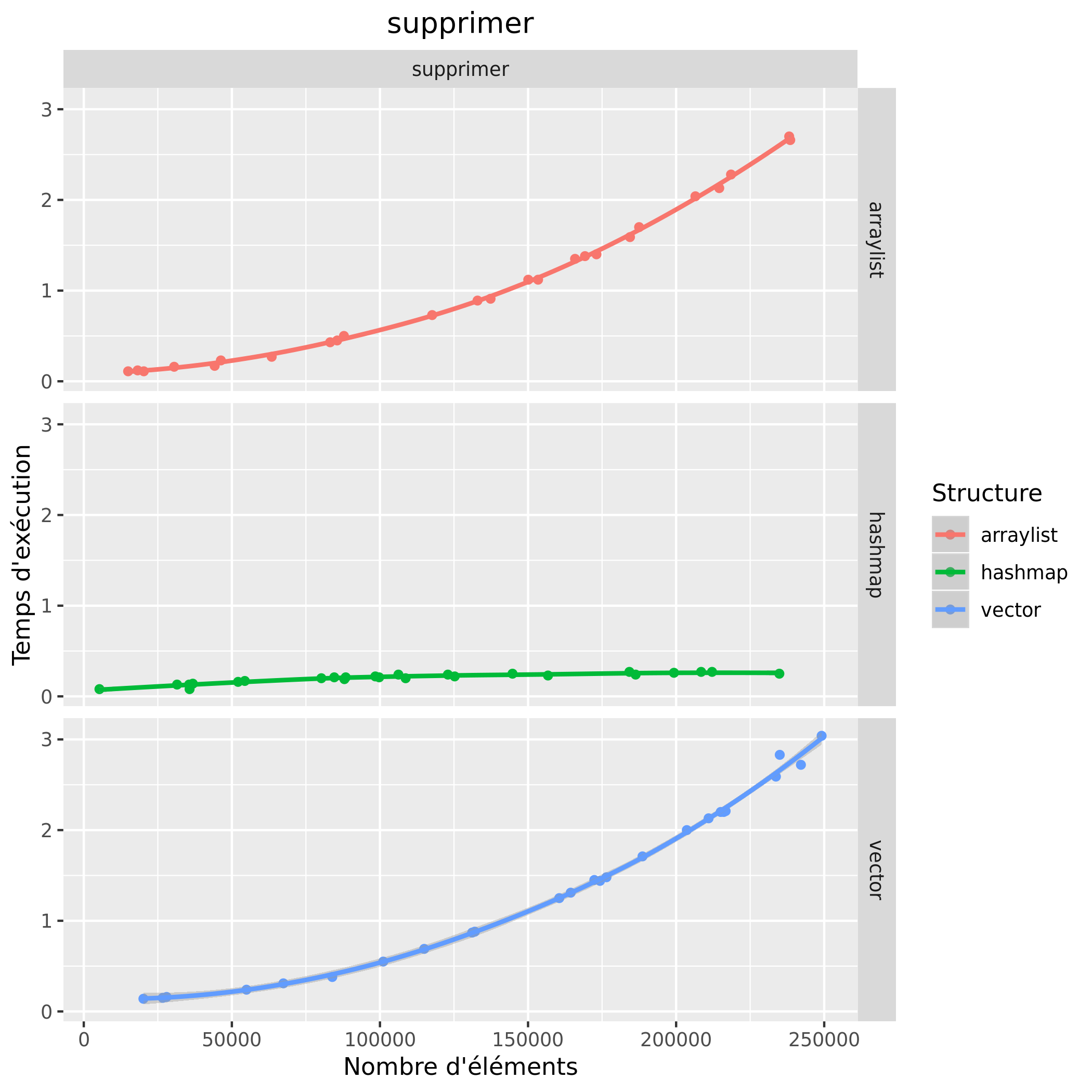
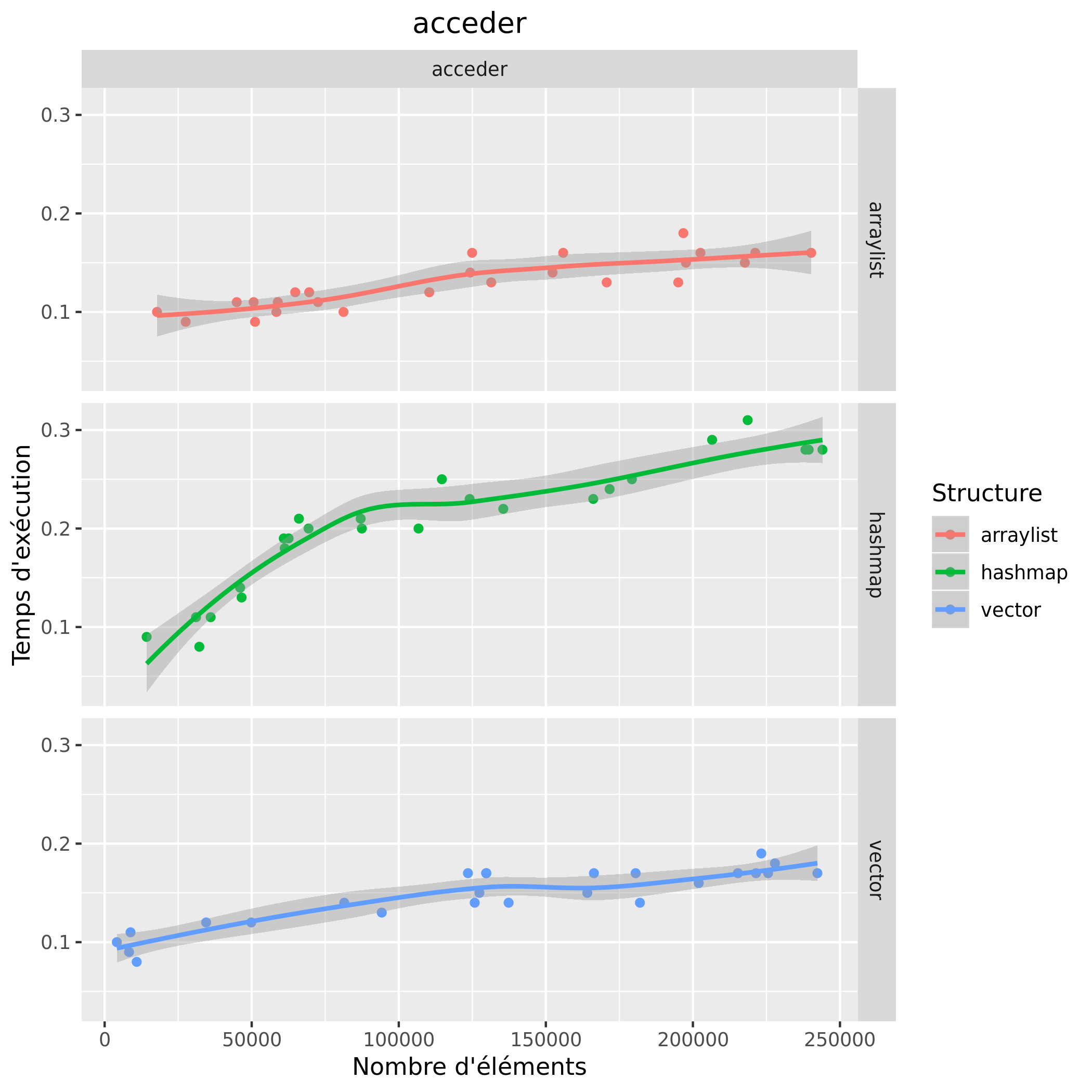
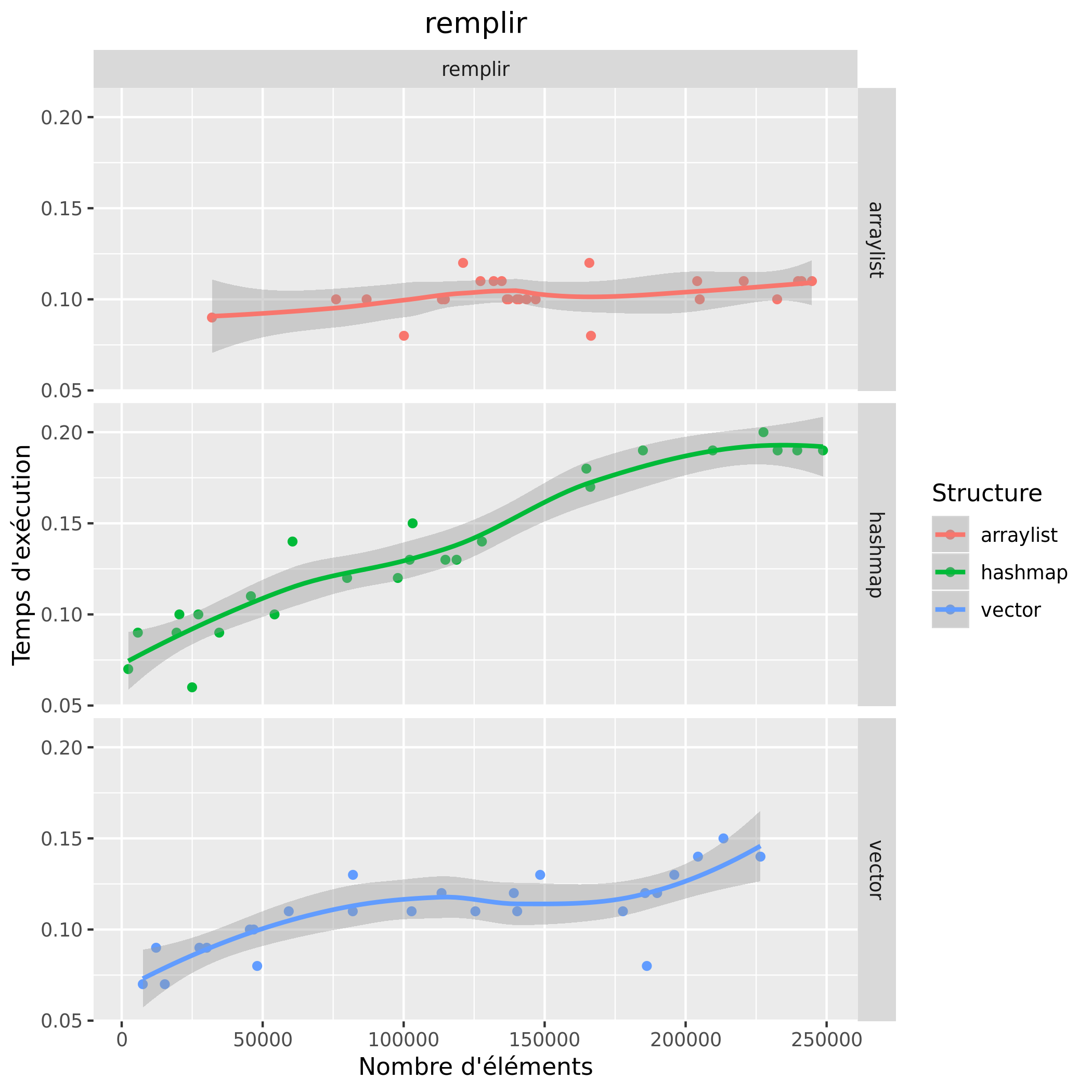
Consommation mémoire
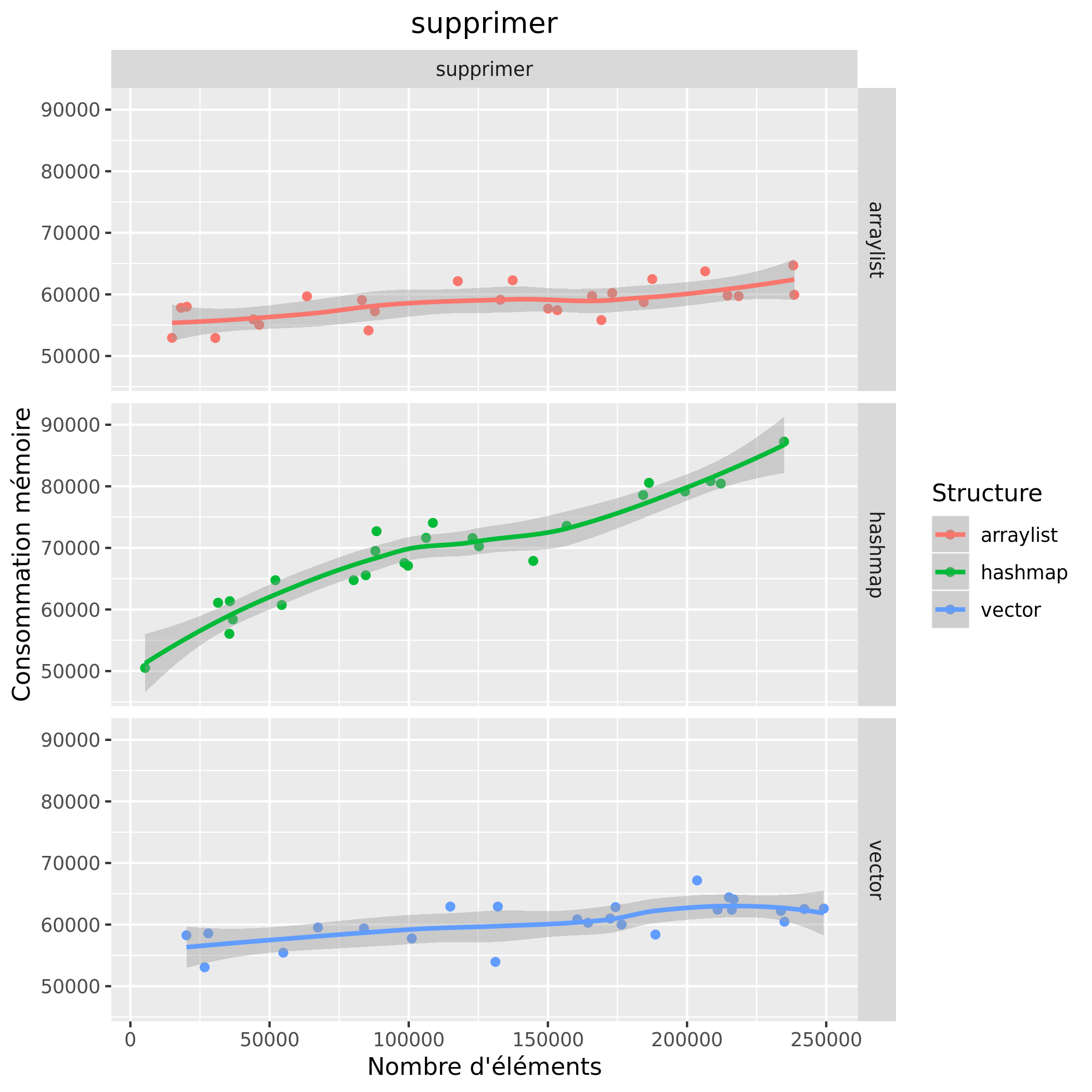
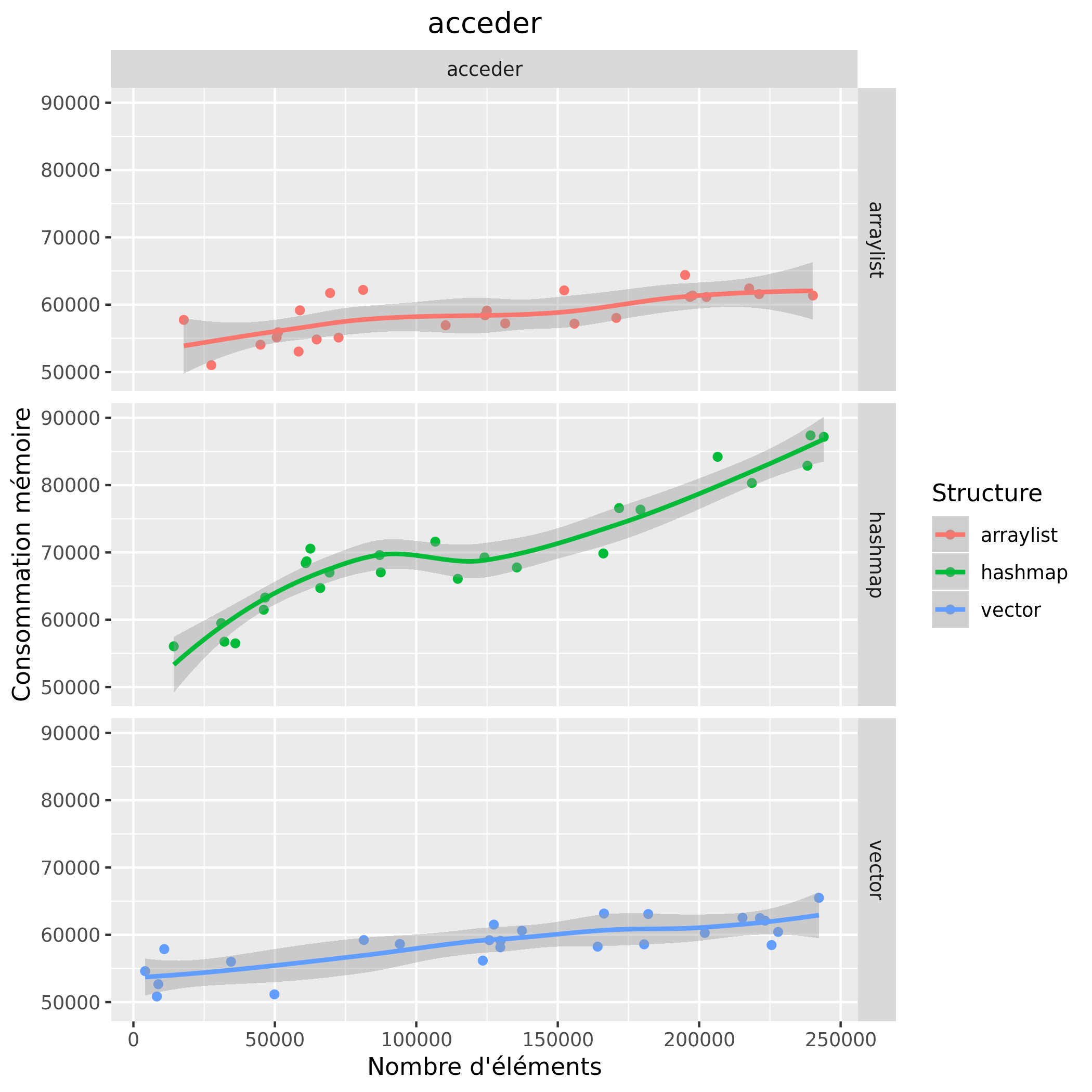
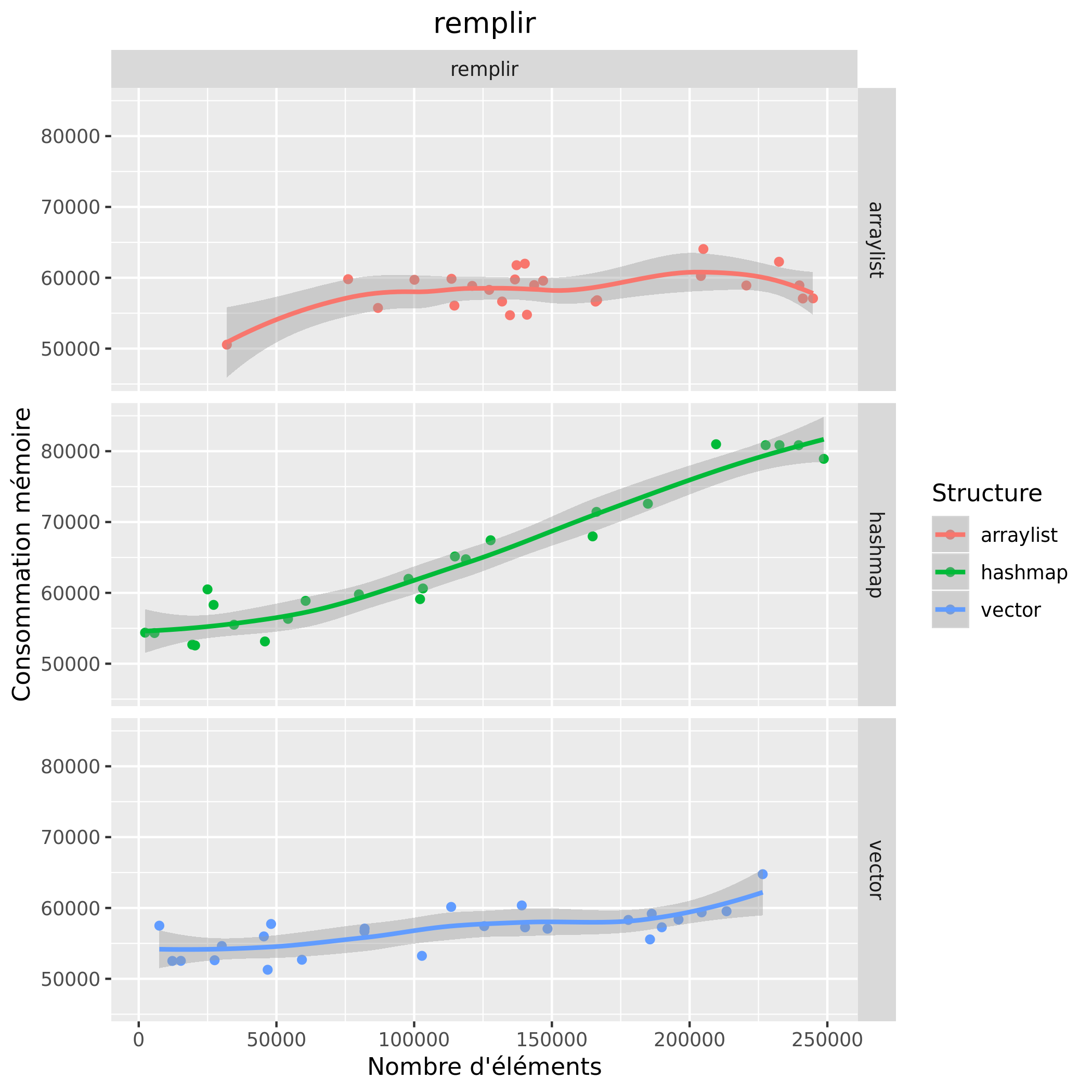
Analyse des résultats préalables
On observe des différences de temps et de consommation mémoire entre les différents graphiques.
Pour le temps d'exécution, on remarque que pour l'opération de suppression, la hashmap est très rapide et que peu importe le nombre d'éléments son temps d'exécution reste globalement le même, les structures arraylist et vector ont, elles, des temps d'exécution qui deviennent de plus en plus importants plus la taille augmente, leurs temps sont aussi similaires. Pour l'opération accéder, on remarque que les temps d'exécution entre l'arraylist et le vector sont similaires et augmentent peu contrairement à la hashmap. Quant à l'opération remplir, l'arraylist reste relativement au même temps d'exécution, on observe une augmentation du temps d'exécution chez le vector est la hashmap, cepedant cette augmentation est plus importante chez la hashmap. En terme de temps d'exécution on observe donc que l'arraylist est une structure offrant des temps faibles quant à l'accès et au remplissage, cependant pour la suppression la hashmap reste la structure la plus rapide ; le vector possède des temps similaires à l'arraylist.
Pour la consommation mémoire, on observe que la hashmap consomme le plus de mémoire et que la consommation augmente linéairement avec le nombre d'éléments. La consommation mémoire des deux autres structures est assez stable, elle n'augmente que très légèrement.
Discussion des résultats préalables
Ces graphiques nous permettent d'avoir un aperçu des consommations mémoire ainsi que des temps d'exécution, cependant certaines valeurs sont bien trop faibles pour conclure, comme par exemple les temps pour accéder avec le vector. De plus les résultats en l'arraylist et le vector sont assez proches, il faudrait effectuer plus de tests afin d'essayer de départager. On remarque aussi que le temps d'exécution pour l'accès avec la hashmap augmente moins à partir de 75000 éléments, en parallèle on remarque une baisse de la consommation mémoire, on ne peut pas tirer de conclusion là-dessus.
Etude approfondie
Hypothèse
Comme vu précédemment, les temps d'exécution et la consommation mémoire des arraylist et vector sont similaires. Or, si le nombre d'éléments dépasse la capacité de l'arraylist, elle verra sa taille augmentée de 50% contrairement à 100% pour le vector. C'est pourquoi, on peut poser l'hypothèse suivante : La consommation mémoire d'une arraylist est inférieure à celle d'un vector ainsi que son temps d'exécution.
Protocole expérimental de vérification de l'hypothèse
Pour ce faire, nous allons modifier le script shell afin de tester avec un nombre d'éléments plus important. Nous ne testerons pas la méthode supprimer car prenant trop de temps. Nous allons tester pour un nombre d'éléments variant de 100 000 à 5 000 000 avec un pas de 50 000.
Suite des commandes, ou script, à exécuter pour produire les données.
./appronfondie.sh |tee perf_hypo.dat
r plot_approfondie.r
Résultats expérimentaux
Temps d'exécution
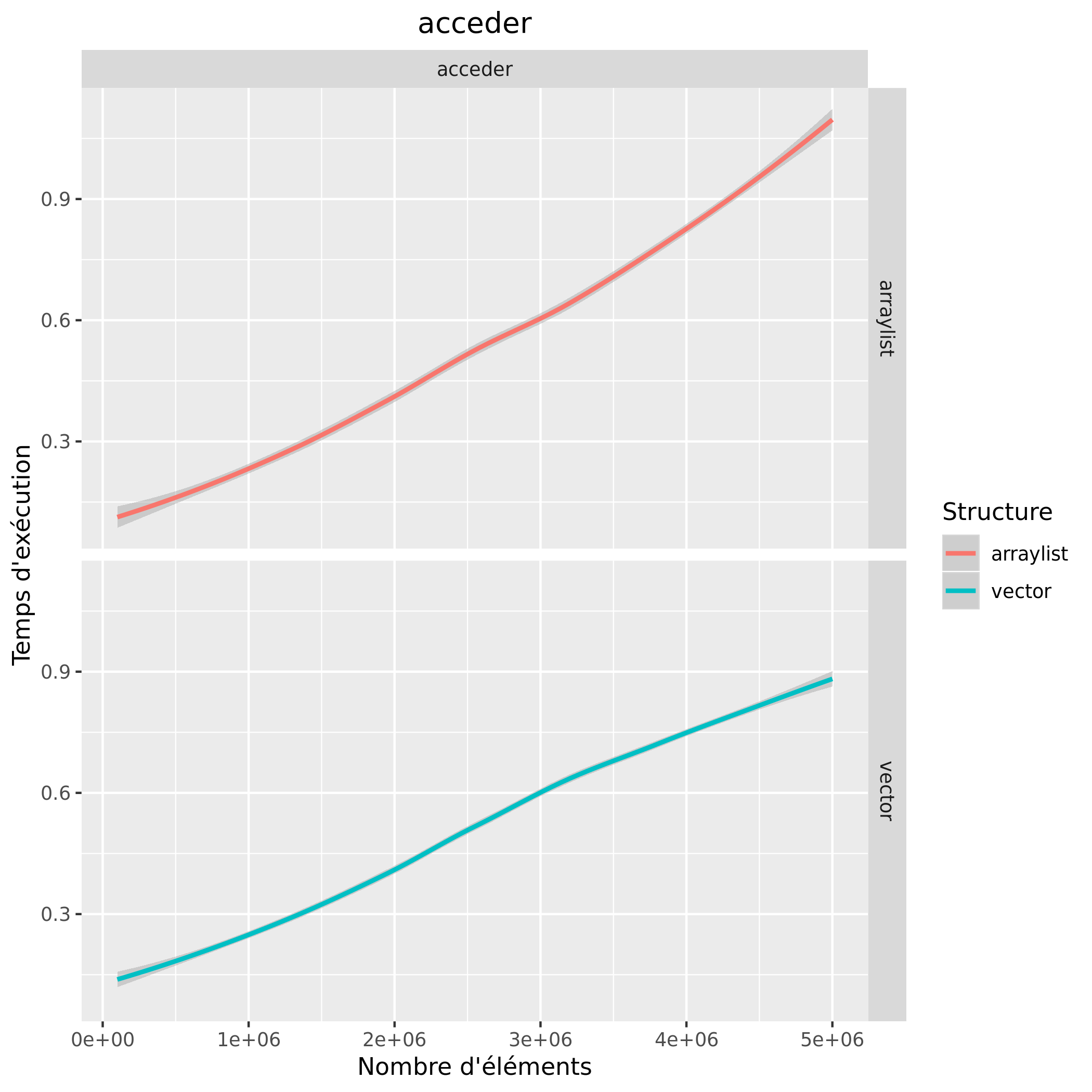
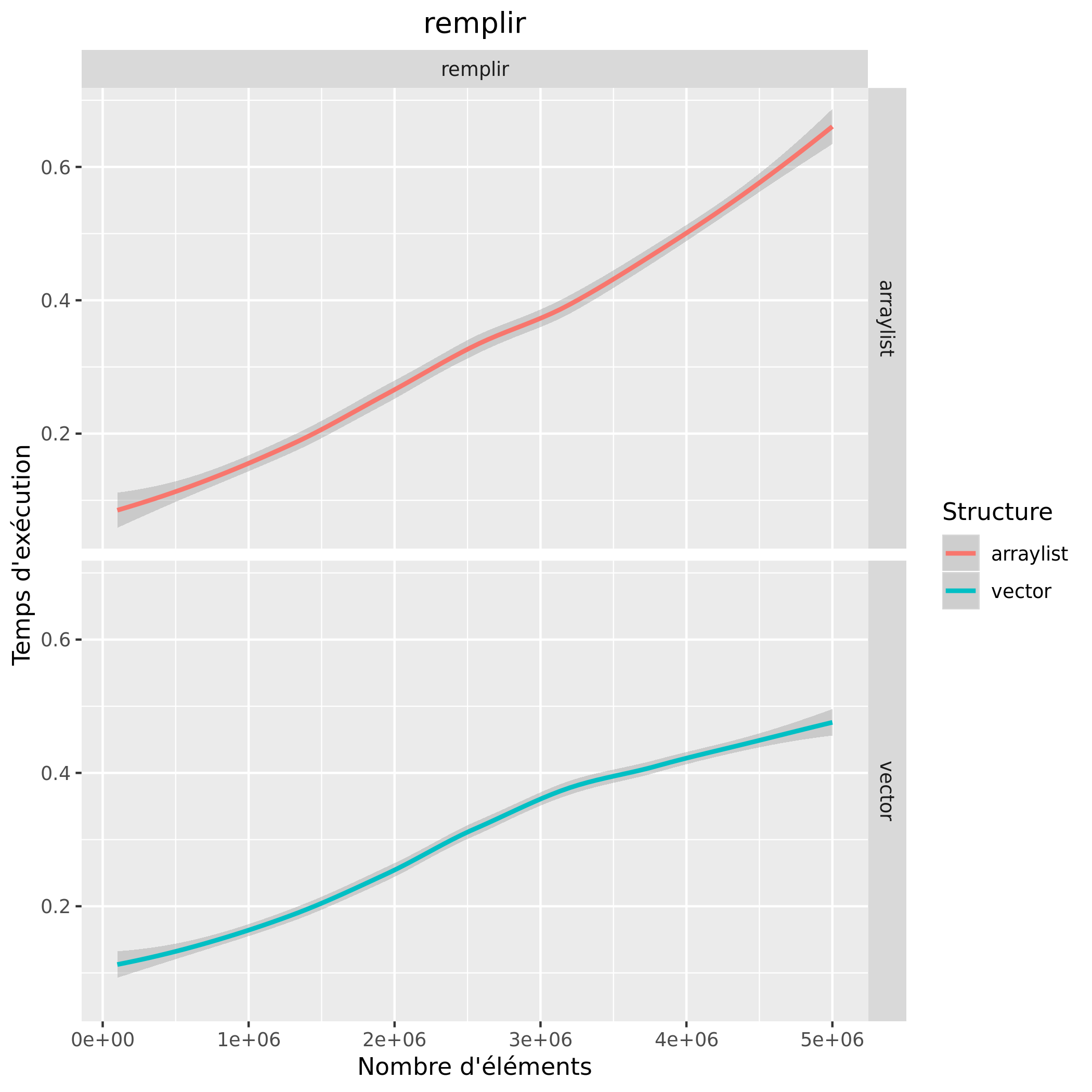
Consommation mémoire
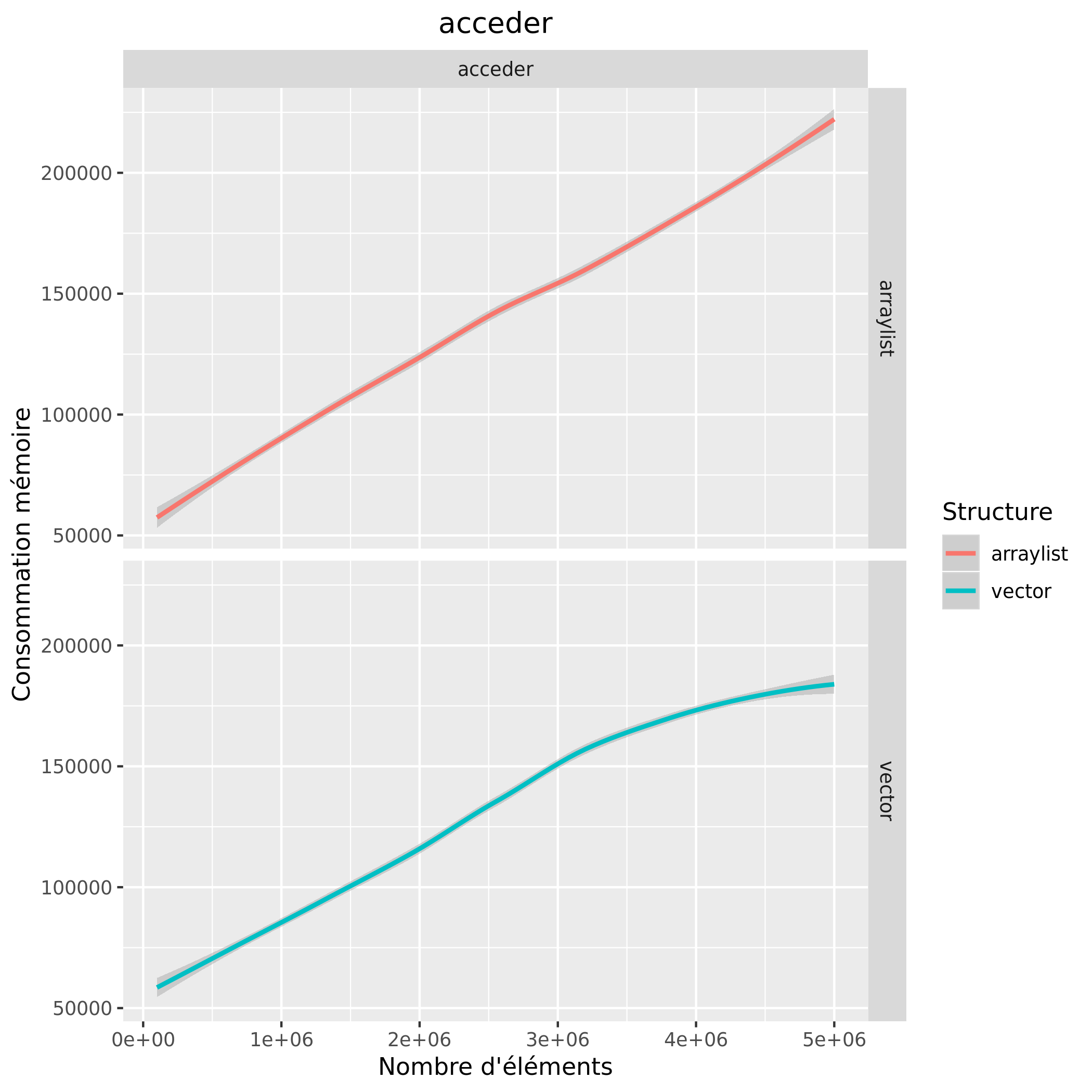
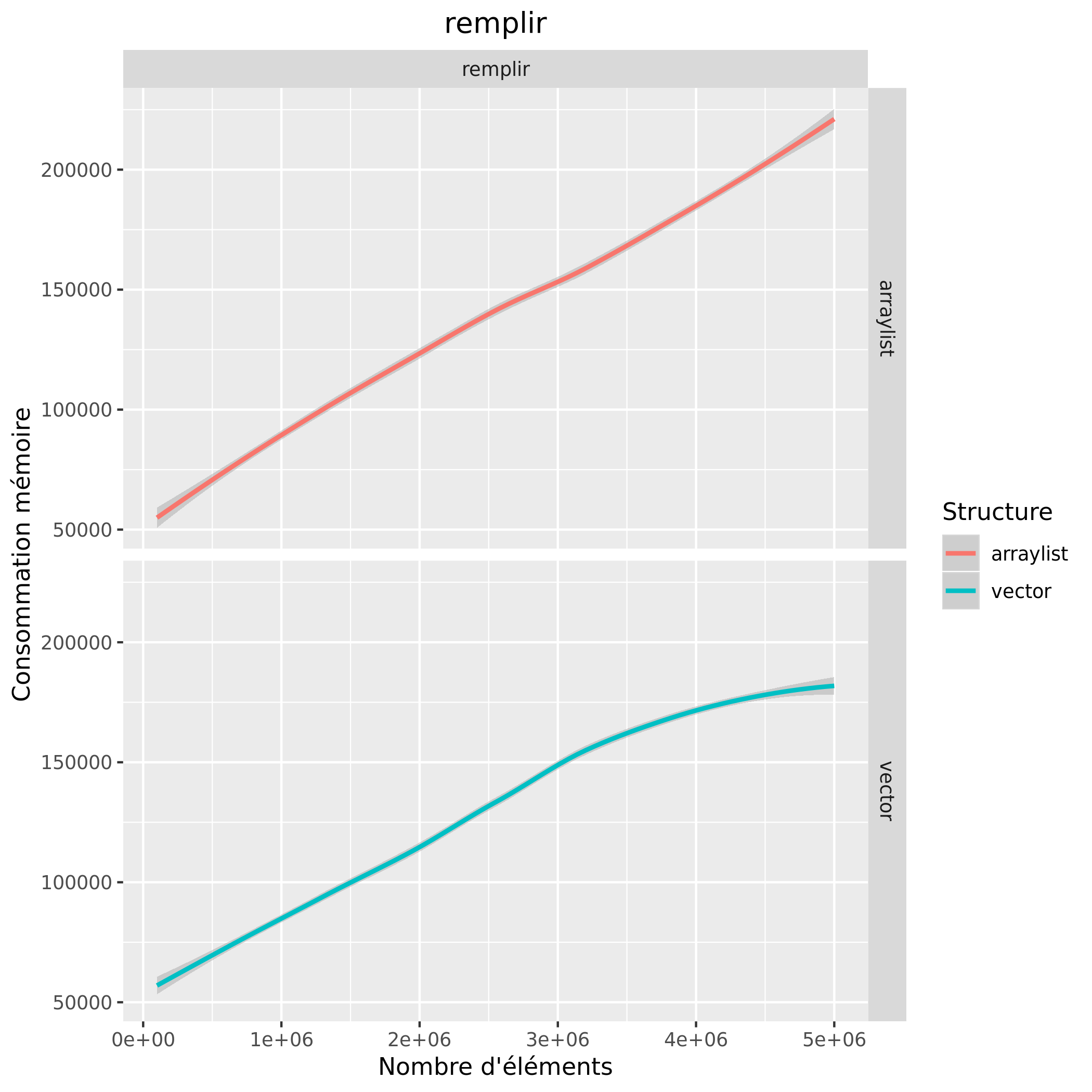
Analyse des résultats expérimentaux
Les courbes restent assez similaires, cependant on remarque quand même que l'accès et le remplissage avec un vector est plus rapide et consomme moins de mémoire.
Discussion des résultats expérimentaux
A la vue des courbes, on peut donc invalider l'hypothèse émise. Finalement, ce n'est pas très étonnant que les courbes soient autant similaires, les vector et arraylist sont des structures très similaires car utilisant toutes deux un array.
Conclusion et travaux futurs
Finalement, on remarque que suivant la structure utilisée et le type d'opération, la consommation mémoire n'est pas la même, idem pour les temps d'exécution. Il convient alors de choisr les structures utilisées en fonction des opérations qui seront les plus utilisées. Par exemple, pour des suppressions à des positions n'étant pas en queue, il est préférable d'utiliser une hashmap.
Pour des travaux futurs, il serait plus intéressant de remplacer le vector par une LinkedList, afin de comparer l'arraylist et la LinkedList. En effet, l'ArrayList implémente une list alors que la LinkedList implémente une liste doublement liée. La différence d'implémentation permettra ainsi de faire des analyses plus intéressantes.